
Marvels of memory auto-configuration (SPD) — Jean Delvare
Serial Presence Detect is a standard used to configure memory.
In the beginning, memory was soldered on the boards directly. The first DRAM module was a 30-pin SIMM from 286 to 486. Everything was hardcoded since there was place for configuration information on it. Then came PPD (Parallel Presence Detect), where 4 pins were used for configuration. It quickly became not enough. and hardware probing or manual configuration was still needed.
Later PPD revisions added more pins, but it didn’t solve the problem nor scale. The need to finer-grained timings information also grew with time, with manual configuration getting more and more complex, to be close to impossible.

When the first DIMM module arrived with the first Pentium generation, SPD replaced PPD. Only 5 pins were needed to configured the data, with serial buses on it, which helped reduce the board footprint. The data was stored in cheap EEPROMs, and all the information was available in up to 256 bytes.
The EEPROMs were compatible with SMBUS and I²C, which means you can use i2cdetect to find them on DDR3 motherboard.
With DDR4, there was a need to have more space to store config parameters. Using bigger EEPROMs have been evaluated, but it proved to bring compatibility issues. So Jedec (the DRAM standard body) decided to define a new EEPROM standard for DDR4. This new standard is named EE1004, and is pin-compatible with the previous standard.
This new standard supports write protection (per block), but is much more complex, Jean found. It abuses the i2c protocol to send commands in addresses, it uses broadcast messages for everything, and isn’t extendable. The spec also includes useless payloads in messages. Since the vendor spec is “crap”, memory modules implemented “crap” on top of it, as Jean says.
Linux support is not essential, Jean says, since in the normal case, only the BIOS or firmware needs to initialize memory. But it’s useful for diagnostics, inventory or knowing the exact memory module to add a similar one. Jean says that dmidecode (which he also maintains) is just not accurate enough on the memory modules.
Drivers for the SMBUS controller and the EEPROMs themselves are needed first for Linux support. There are then userspace tools, the main one which Jean also maintains: decode-dimms. It’s a perl scripts that parses the information of all DDR to DDR4 EEPROM information.
An issue we have today in Linux is that the EEPROM devices need to be instantiated before the SPD information can be fetched and parsed. Jean is working on adding automatic probing based on DMI data and I²C probing on the SMBUS, in order to automatically instantiate the appropriate device on responsive addresses.
XDP closer integration with network stack — Jesper Dangaard Brouer
XDP was needed for the kernel networking stack to stay relevant, amidst the emergence of kernel-bypass technologies. Jesper’s goal is to stay within 10% of similar kernel bypass technologies.

It’s designed as a new, programmable layer in front of the network stack, allowing to read, modify, drop, redirect or pass packages before they go into the kernel network stack.
AF_XDP is used to provide kernel bypass of the netstack. DPDK, a competing technology already integrates a poll-mode for AF_XDP. The advantages of AF_XDP, is that it allows sharing NIC (network card) resources.
XDP is faster because it bypasses allocation, and lets you skip kernel network code. But skipping the network stack means you can’t benefit from its features. So it might be needed to re-implement them. To avoid this reimplementation, XDP enables adding BPF-helpers instead to share resources.
Jesper want people to see XDP as a software offload for the kernel network stack. An example of work in this area is accelerated routing or bridging in XDP, but with fallback to the kernel network stack for non-accelerated packets.
One goal of Jesper is to move SKB allocations outside of NIC drivers, in order to simplify the drivers, by creating the SKB inside the network-core code, this already works with xdp_frame and the veth driver and cpumap BPF type. But there are still a few roadblocks for that with various types of hardware offloads used by SKBs that need to be taken care of.
Jesper has a few ideas on how to solve this, and he wants to add a generic offload-info layer, and is looking for input on how to implement it. The generic offload-info also needs to be dynamic so that each driver has its own format for hardware description.
Another issue for network-core SKB alloc is to have XDP handling for multi-frame packets. Jesper says that this issue has been ignored for a while, but that it’s time to have proper handling for the multi-frame packets use cases: jumbo frames, TSO, header split.
Having generic xdp_frame handling has a few advantages: it can help add a fastpath for packet forwarding for example.
Many people complain that XDP and eBPF are hard to use. That’s why Jesper created a hands-on tutorial with a full testlab environment, that he releases today at Kernel Recipes.
Jesper says that XDP is missing a transmit hook. This is more complex than it sounds, because it needs a push-back and flow-control mechanic, but without reimplementing the qdisc layer that already does that in Linux.
In conclusion, there are a few areas that still need work in XDP, and Jesper says that contributions are welcome to address the many needs.
Faster IO through io_uring — Jens Axboe
The synchronous I/O operations syscalls in Linux are well known, and evolved organically. Asynchronous operations with aio and libaio don’t support buffered I/O, O_DIRECT isn’t always asynchronous and aio is generally syscall-heavy, which is quite costly in a post-speculation mitigations era.
This lead to Jens to write a wishlist of asynchronous I/O features. He wondered if it was possible to fix aio. After a fair amount of work, he gave up and designed his own interface: io_uring.

He met quite a bit of resistance from Linus, who was burned with previous asynchronous and direct I/O attempts that have little usage. It was still merged in 5.1, with more features added in recent releases.
Fundamentally, io_uring is a ring-based communication channel. It has a submission queue (sqe), and a completion queue (cqe). It’s setup with the io_uring_setup syscall that returns a ring file descriptor, and takes a big struct with parameters.
Ring access is done through memory mapping. Reading and writing the ring works with a head and tail indexes that are common to ring data structures.
To send a new sqe, one reads the current tail, verifies if the ring won’t be full, writes data just after the tail, then updates its index in two steps with write barriers between each. For cqe, it works a bit similarly.
To submit requests, one uses the io_uring_enter syscall, which enables both submit and complete at the same time.
Jens says that if this looks a bit complex, it’s because it’s not made to be used directly in an app. There’s liburing for that which handles the complexity of ring access behind the scenes.
liburing has various helpers to the multiple commands supported by io_uring (read/write/recv/send/poll/sync, etc.). It has a few features: it’s possible to wait for the previous command to drain. It’s possible to link (chain) multiple commands, like write->write->write->fsync. There’s also an example to do direct copy of an arbitrary offset within a file to another within another file in examples/link-cp.c.
It supports multiple features based on registering aux functions for advanced features, like eventfd completion notifications.
Polled IO is useful when wants to trade CPU usage for latency. It’s supported automatically by ioring at setup time, but can’t be mixed with non-polled IO. It’s also possible to do polled IO submission where reaping is app-polled in order to do I/O without a single syscall.
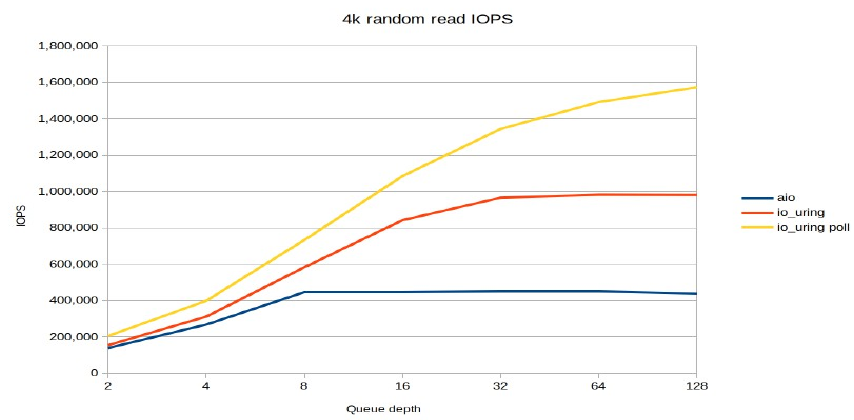
In addition to having better raw IOPS and buffered read performance, io_uring also has better latency.
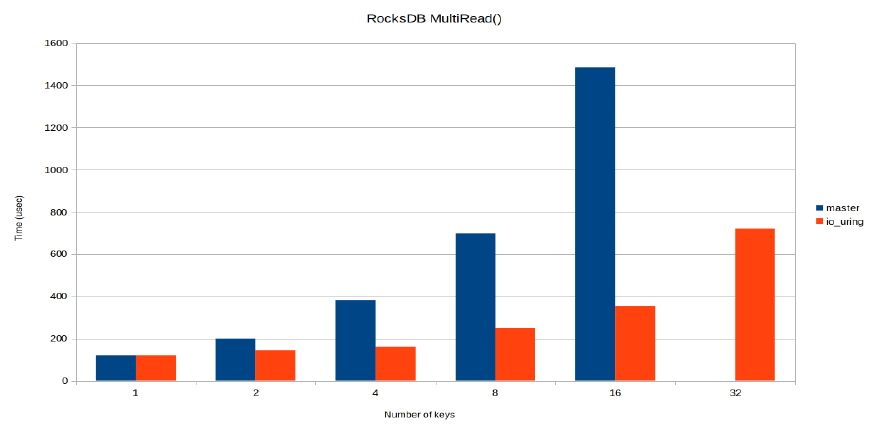
Adoption is really growing, with interest in the Rust and C++ communities, in Ceph, libuv and postgresql. In RocksDB, the MultiRead() performance greatly improved:
A simple single thread echo server written by @CondyChen showed better performance than with epoll. Intel has also had great NVMe improvements on IOPS from 500k to 1-2M IOPS when using io_uring vs aio.
In the future, Jens imagines any high perfomance syscall that needs to be fully async could be implemented on top of io_uring. Jens maintains a definitive documentation of io_uring, which is being updated regularly.
The next steps toward Software Freedom for Linux — Bradley Kuhn
Bradely first downloaded Linux in 1992, and didn’t boot it before 1993. Although he because a Free Software activist, he started as a computer science student who built a Linux-based lab in 1993. He had to patch the kernel to remove ctrl-alt-del to prevent any local user from rebooting the machine and disconnecting remote students.
That’s when he did this small modification by using the fundamental freedom provided by the GPL which Linux used, that he understood how important it was.

The freedom the first kernel developers had to hack on their own devices led to a very useful OS. The first Linksys WRT router used Linux because of this. But it was also the first massively sold GPL-violating device. Once this violation was resolved, this lead to the creation of the OpenWRT community, which gave even more freedom to the users.
With time, more routers were released violating the GPL, which Harald Welte helped resolve, sometimes with litigation. This helped the OpenWRT project being ported to even more projects.
Bradley says that Linux is the most successful GPL software project out there. But to stay there, it needs users to be able to continue installing their modifications and tinkering.
GPL enforcement is a necessary part for that, Bradley says. Although he doesn’t support malicious enforcers that want to get rich out of it. He says that Software Freedom Conservancy is available to help do ethical GPL enforcement.
That’s it for today ! Conitinue with the last day live coverage.
Trackbacks/Pingbacks