Welcome to the Kernel Recipes Liveblog ! This follows yesterday afternoon’s liveblog.
Meltdown and spectre: seeing through the magician tricks — Paolo Bonzini
A commonality of modern computers is privilege separation. The modern OSes rely on the processor hardware for help in order to do this. The main idea behind Spectre and Meltdown is that the OS can’t do that if the hardware doesn’t help.
Modern CPUs usually execute instruction within a pipeline, which every phase being done in parallel (Fetch, Decode, Execute, Writeback is a simple pipeline modelization). The issue when executing conditional branches is that you never know which side of a branch will be executed, which means you might have to block the pipeline until you have the information. Or you can use branch prediction, and try to guess which condition will be correct. If the guess is wrong, the pipeline needs to be flushed.
Static branch prediction already gives you very good results, between 70% and 80% correct guesses, Paolo says. But modern CPUs use dynamic branch prediction, with more and more predicting techniques: store bias (1977), store history (1991), multilevel, neural network predictors, geometric predictors; it’s a very wide field. The goal is always to improve the pipelining, to try to predict as many correct branches as possible.
Another CPU trick, is superscalar execution and scheduling. Which means that you can execute more than one instruction per cycle. It needs proper ordering of instructions though, and the compiler help, like in the infamous Itanium architecture.
Out-of-order execution is another trick that is used to improve execution speed, that is done in-CPU. It reorders instructions to execute what’s possible to execute at a given stage in the pipeline, while it waits for memory fetching, or resolution of other instructions. Once all previous instructions are executed, an instruction can “retire”, which is another stage in a pipeline. It’s more efficient than the superscalar mode, Paolo says.
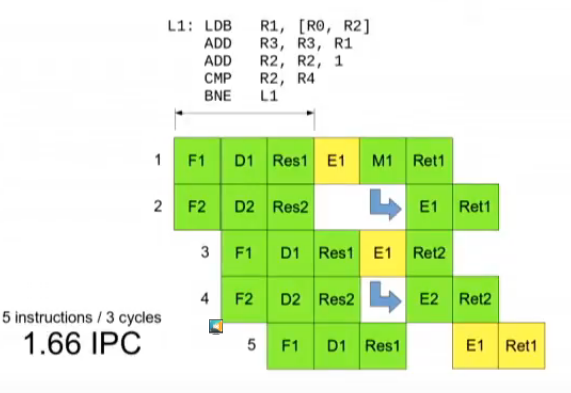
Speculative execution can then be added on top. The processor will continue executing more instructions before knowing if an instruction can retire. It greatly improves speed upon correct branch prediction, and in case of flush, it’s as slow if the CPU had waited for an instruction to retire.
Caches add yet another layer of complexity: they are pervasively used because they help with memory access, which is much slower than CPUs. Cached data or instructions are much faster to fetch than in memory. The issue is that you can have cache side-channel attacks, by measuring the time it took to fetch a bit of memory, in order to know whether it was in cache or not.
Spectre
The idea behind a Spectre is that you find a memory load with an address the attacker controls. You then train the branch predictor to execute the memory load speculatively. Then you need a second access with an address that depends on the first value you read. Measuring the cache access time after that lets you read leaked data.
So how to work around this ? It can be done in source or at the compiler level. This is mostly done by hand now, Paolo says, at privilege boundaries.
Meltdown
Meltdown relies on paging: each program has a different memory mapping, and page faults happen when trying to access a memory address it doesn’t have access to. Meltdown relies on speculative execution behind page faults, meaning you can observe cache-side effects of speculatively-executed instructions on a memory address the program doesn’t have access to.
A work around this is to separate page tables between supervisor mode (kernel) and the user processes. Which means the kernel is no longer mapped user programs, but you need to do expensive TLB flush at privileges boundaries.
Another thing that can be done, is to add checks to the cache and hide the content of cache lines if the permission checks fail. This change needs new hardware and updated microcode is not enough to fix Meltdown.

To conclude, Paolo said that hardware help to mitigate these attacks will arrive, in time. And not to panic, because these are neither the first nor the last hardware bugs.
Mitigating Spectre and Meltdown (and L1TF) — David Woodhouse

A speculative execution attack, David says, has three components. First, a way to enter speculative execution: a conditional branch, an indirect branch, an exception, or TSX (Intel transactional memory extensions). Then, you need a way to prolonge the speculative the execution: with a data load, dependent loads, or dependent arithmetic. Finally, you need a way to leak data: through the data cache, which was seen in the wild or others that are theoretically possible: the instruction cache, the prediction cache or the translation cache.
Meltdown allows direct read from non-permitted (kernel) memory. It runs entirely in userspace, which means the kernel can’t notice anything happening. It works on Intel (not AMD), POWER, and ARM Cortex-A75, David says.
Spectre v2 is based on indirect branches, and v1 on conditional branches. The userspace attacking the kernel needs to have two loads in a row inside the kernel, with the first one being from an address controlled by userspace.
To mitigate Meltdown, KPTI/Kaiser relies on changing the page table when going into the kernel. Which means each process has two sets of page tables.
Spectre Mitigations
Spectre v2 mitigation relies on microcode features. There are new functions in MSRs (Model-specific registers): IBRS and IBPB which allows restricting speculation, and flush the branch prediction. Linux still doesn’t use these new expensive instructions
What’s currently to mitigate spectre v2 used are retpolines, a way to fool the branch predictor. Any indirect branch (when jumping on an address), when using function pointers will cause a full branch predictor flush and a “pipeline stall” David says, which has a huge performance impact, since Linux relies a lot on function pointers.
To “get the performance back”, the solution is to call functions directly, or to inline functions which take callback functions as arguments. Inlining an iterator function can help the compiler emit a direct call, and get much better performance in loops.
Even with all its problems retpoline is still much more performant than the IBRS instructions.
The return stack buffer also needs to be cleared, because modern Intel CPUs (Skylake onwards), prediction happens on the ret instruction as well, so it’s cleared with a trick on VMEXIT and context switch.
For Spectre v1, the new array_index_nospec() adds data dependency in bounds checking, and needs to be added manually at the proper places, like get_user() David says.
L1 Terminal Fault (L1TF)
This attack, announced last months, allows a VM guest, to ready any memory in a sibling hyper-thread CPU, as long as it’s loaded in the L1 cache. It relies on controling the PTEs in the VM guest, on which the CPU will execute speculative instructions.
To work around this, a patchset has been posted to prevent running different VM guests on sibling cores. It’s a lot of work, but there’s a big motivation to do it now, David says.
In conclusion, on Linux today, there are many mitigations: retpolines, IBRS on firmware calls, IBPB on VM context switches, RSB is cleared, dcache is cleared on kernel exit. Unfortunately, on Skylake and later, there are still unsolved speculations, in many places. Xen is better, David says, since it cleares IBRS and IBPB when needed, and you don’t need to “pray”, when using a recent CPU.
ObsBox: a Linux-based real-time system for LHC beam monitoring — Miguel Ojeda
Miguel works for CERN, as a software engineer, and is the second person on stage this year to admit liking C++.
At CERN, they work on particle physics, which is really easy, Miguel says. It only has 9 simple steps: first, you accelerate the particules, then smash them in opposite directions. You detect the collisions byproducts, filter the in real-time huge amounts of data, store what is deemed important losing everything else. You repeat this, and then analyse to the data to test if the the expectations match reality. Miguel says the last step is to get a Nobel prize.
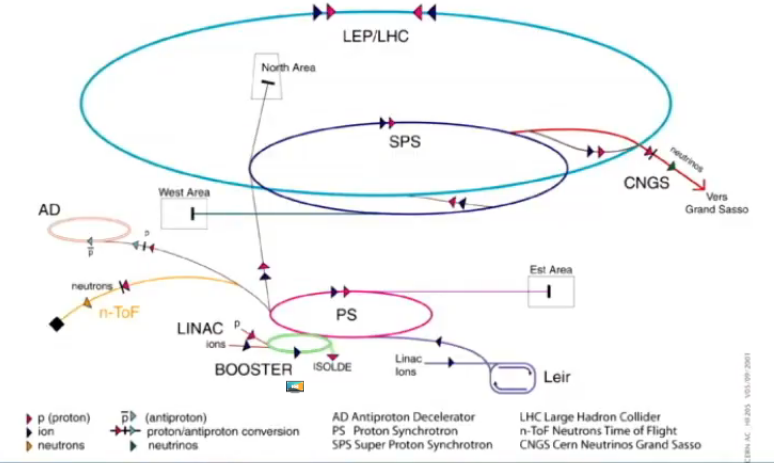
The LHC is the last step in a chain of particle accelerators, all starting in a simple bottle of hydrogen. A single proton is accelerated to just 11km/h below the speed of light.
A collision happens every 25ns, and there many type of detectors to measure the effects of this event. All the data can’t be stored, so it has to be filtered in real time.
This data is then analyzed, and reused in simulations, in order to infer, with a certain degree of confidence, what happened.
To make all of this work, this requires a lot of computer science. There’s a lot of C++, and a lot of Python. They regularly find compiler bugs for example. Miguel helped CERN move from CVS to git, for the collision detection software (CMS).
ObsBox is Linux system that is used to capture data out of the detections systems. Both the hardware and software was designed in-house at CERN.
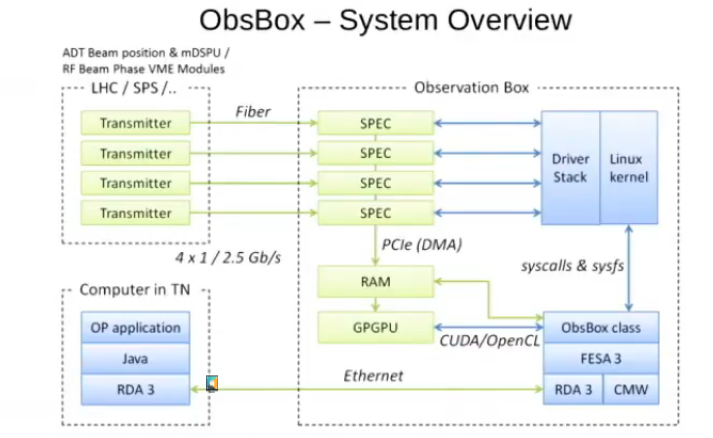
They use the Linux with real-time patches. The system was relatively successful inside CERN, so that other teams were interested in doing the same. Using off-the-shelf hardware (FPGAs, and rackable Supermicro linux servers), greatly reduced the cost compared to high-end oscilloscopes.
The driver Miguel wrote is as simple as possible, he says, only needing to support read() operations for acquisitions, the rest being doing in userspace.
In conclusion, Miguel says that Linux is a great match for CERN needs because it’s freely available, and easy to customize and extend.
That’s it for this morning. Continue with the afternoon liveblog!