Welcome to the Kernel Recipes Liveblog ! This follows the morning liveblog.
From knowing the definition of Linux kernel to becoming a kernel hacker — Vaishali Thakkar
Vaishali want to recount how she became a kernel hacker. She initially thought that to be kernel programmer, you had to be a wizard C programmer.
Unfortunately, she learned about programming at university using Turbo C, an environment very different to Linux+gcc. The linux kernel was described very briefly, and Unix commands were learned on paper.
Last but not least, she said english is not her mother-tongue, and she learned it pretty late so this was another barrier.
A very bad thing then happened to here: she got a leg fracture. But this was the starting point of her Linux journey. Freed of assignments, she could install a Linux distro on her computer, and take time to read a Linux book. Her discovery of GCC was mind-opening, and she decided to re-learn C programming.
Shortly after, she found the outreachy project, with maintainers giving specific tasks. She was accepted, which then helped her find an internship, and then a job, before she started doing freelancing.
 Then she asks: do you really need to get a fracture to become a kernel hacker ? Of course not. It’s important to have a growth mindset; which means that you’re always ready to learn and understand your blind spots so you can improve. But is a positive attitude just enough to become a kernel hacker ? Again, she says it’s not sufficient. You need to put in the efforts, and you also need to learn self learning skills.
Then she asks: do you really need to get a fracture to become a kernel hacker ? Of course not. It’s important to have a growth mindset; which means that you’re always ready to learn and understand your blind spots so you can improve. But is a positive attitude just enough to become a kernel hacker ? Again, she says it’s not sufficient. You need to put in the efforts, and you also need to learn self learning skills.
Knowing how to find the right resources: from source code, to LWN articles, to mailing list archives, to git history/blame, to going to conference talks like Kernel Recipes.
Asking questions is also important, especially from Vaishali’s background where it wasn’t really celebrated. And you need to understand the difference between a good and bad question, as well as the sub-project mailing list etiquette. Various maintainers have various preferred style of approaching issues and patch submission, which is something you must understand.
Automating the learning is also important. Using tools to augment the speed at which you “git grep”, from inside you editor for example. Writing your own support scripts is also very useful to reduce repetitive patterns.
You also need to keep your kernel knowledge updated: APIs evolve, submissions processes, and you need to understand this.
Last but not least, improving your general programming skills: understanding of what is intelligent or bad code, learning from other developers.
In response to a question from the audience, on what could be improved to the onboarding process of kernel developers, she said that a proper TODO would go a long way to help find new tasks, and she’s maintaining her own TODO list for newcomers.
Live (Kernel) Patching: status quo and status futurus — Jiri Kosina
Why is it interesting to live-patch a kernel instead of rebooting ? Downtime has a huge hourly cost, more than $100K for many enterprises, Jiri says. Live kernel patching is for changes that are outside of the planned maintenance window, when you need to act quickly.
History
It all started in the 1940s, with punch-card based computers, where differently-colored punch cards would be replaced at runtime to fix bugs without downtime. In 2008, ksplice was started originally as research project to live-patch Linux, then acquired by Oracle in 2011, and source closed before commercial deployment.
In 2014 an interesting collision happened: kPatch and kGraft were released a few weeks apart, the first one from Redhat, and the second one SUSE. Both were commercially deployed
CRIU (Checkpoint/Restart in Userspace) was also another solution circa 2008, but it wasn’t really immediate since it required hardware reset.
This is how kgraft/kpatch work, simplified, by using a trampoline to replace buggy_func with fixed_func: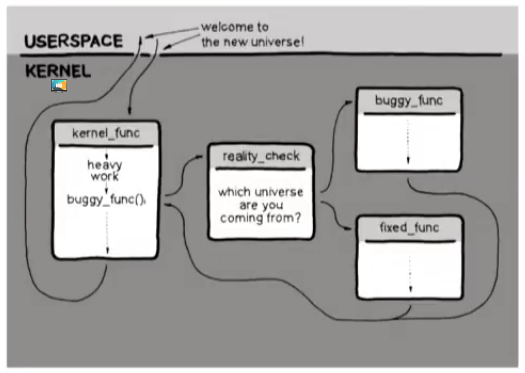
In 2015, Redhat and Suse agreed to cherry-pick individual features of each of their patchset and “merge” there approaches, with the core being upstream.
Live patching was initially x86-only, and now works on s390, ppc64 and arm64.
With the upstream livepatch infrastructure, patch generation is mostly done by hand, Jiri says. It comes in the form of a C file, that will be loaded as a kernel module.
Limitations and missing features

Currently, there’s a limited ability to deal with a data structure change, or semantic changes. The new functions need to understand both the old and new data format. Transforming data structures on access is possible, but only after lazy migration is complete.
Shadow variables is a new feature that was merged, that allows associating new fields to an existing structure, which can then be used by patched callers.
When system state contains locking mechanisms, it’s almost impossible to livepatch without stopping the system.
Trying to know when a change is or isn’t within the consistency model is very difficult. For example, you can’t really patch schedule(), or static variables in a function scope.
There’s some tooling, with a patched GCC, to find when a function has been inlined, and then fixing all the function sites where it is included.
Kprobe transferring is also missing, since there’s no match between the old function, and the patched version yet. Steven Rostedt in the room says that it could be fixable.
Extending to new architectures needs support for FTRACE_WITH_REGS, as well as a reliable stack unwinding.
There’s the inability to patch hand-written assembly, because it’s not ftrace aware, which the livepatching infrastructure uses. It’s possible in theory, but complex. Userspace patching is something that could be done, but is a different problem entirely: there’s no consistency definition, and while the kernel (and livepatch) heavily rely on GCC, it’s not the same in userspace. There are a few projects that attempt to do that, though.
Jiri then shared exclusively that SUSE is currently working on a way to patch only the system libraries by tracking the boundaries (PLT entry/trampoline return), which should be published soon.
CPU Isolation — Frédéric Weisbecker
What is CPU isolation ? It’s when you want to the full processing power for your use, without interference from other CPUs.
Kernel isolation is hard. It’s made of tradeoffs, and often requires sacrificing something, Frédéric says.
Task affinity can be used to assign a task to a CPU. For kernel threads, you can do the same sched_setaffinity(), but unbound workqueues are a special case. Unfortunately, per-CPU kThreads can’t be affined.
 IRQ affinity is possible as well, but requires understanding the correct level at which to affine them.
IRQ affinity is possible as well, but requires understanding the correct level at which to affine them.
For time IRQs, there’s no general rule, and you need to understand the timer associated with your IRQ, Frédéric says. For example, with the watchdog hrtimer, you can disable it partially with a cpumask, or entirely, although this isn’t advised. For the clocksource_watchdog, Frédéric says, the only solution is to change your hardware. Or use the black magic tsc=reliable boot option, which shouldn’t be used in production.
Nowadays, many Linux distributions enable CONFIG_NO_HZ_FULL at compile time, which disables the tick timer entirely; but you need to pass a kernel command line argument to enable it. Frédéric says it does not come for free, as there’s still overhead: you still have tick reprogramming on IRQ exit and context switch. There’s also overhead on kernel entry/exit (syscalls, exceptions, faults) for cpu time accounting, since you don’t have a tick anymore to maintain it.
Nohz requires running only one task at a time, and avoiding kernel entries entirely in order not to affect per-CPU async code in the kernel (kthreads, timers, workqueues, RCU, etc.).
Nohz housekeeping is “the lamb to be sacrificed”, Frédéric says. You still have a 1Hz CPU 0 tick, for timekeeping for example.
To have proper userspace CPU isolation, you need to avoid syscalls entirely. Some extreme cases reimplement kernel features in userspace, like TCP stack for example.
To do all that, Frédéric says it would be nice to have a unified interface to do this. He tried to extend isolcpus= to replace nohz_full= he said, but it might be better to use cpusets.
The power supply subsystem — Sebastian Reichel
 The power-supply subsystem includes smart batteries, chargers, and currently lives in drivers/power/supply. Sebastian took over the maintainership of the subsystem when he was trying to submit a patch, and the maintainer wasn’t responding and had disappeared.
The power-supply subsystem includes smart batteries, chargers, and currently lives in drivers/power/supply. Sebastian took over the maintainership of the subsystem when he was trying to submit a patch, and the maintainer wasn’t responding and had disappeared.
A recent modification, he said, was big improvements by Adam Thomson to the documentation. Adam also added the usb_type property, which shows all supported modes, and allows changing mode.
Another addition, by Liam Breck, was support for dumb battery description, which don’t have their own smart charging circuits.
A current limitation, is the missing support for batteries that have multiple fuel-gauges, since only one is exposed to userspace; there is still no solution for this.
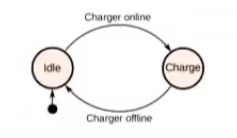
The current framework expects the chargers to work autonomously, as is done on x86 by the EC controller, but this is not true in embedded devices, which might need handling from kernel.
A year of fixing Coverity issues all over the kernel — Gustavo A. R. Silva
Coverity is a static code analyzer, that analyzes the code, but generates a lot of false positives. Gustavo says he spens a lot of time trying to understand what constitutes an actual bug. The high-impact issues include out-of-bound accesses, resource leaks or non-initialized variables, and medium-impact include NULL-dereference or control flow issues, for example.
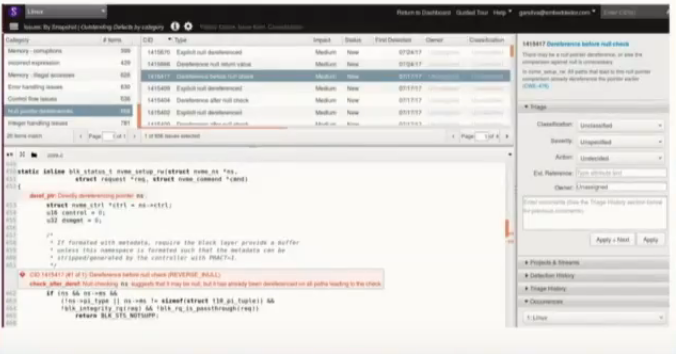
He showed different examples of buggy code, which he fixed in the kernel. Incorrect variable type (size), unreachable code, an infinite loop which led to out-of-bounds access, integer overflows or user-after-free errors.
 As part of his workflow, Gustavo reviews daily Coverity reports. He started recently using Smatch to find spectre v1 issues. He uses a lot Coccinelle (presented this morning at kernel recipes): writing and running scripts. He also modified his sleep schedule to wake-up earlier, in order to fix issues faster when the daily Coverity reports arrive, as part as a friendly competition with a Canonical kernel developer.
As part of his workflow, Gustavo reviews daily Coverity reports. He started recently using Smatch to find spectre v1 issues. He uses a lot Coccinelle (presented this morning at kernel recipes): writing and running scripts. He also modified his sleep schedule to wake-up earlier, in order to fix issues faster when the daily Coverity reports arrive, as part as a friendly competition with a Canonical kernel developer.
Gustavo says he’s submitted 750+ patches since last the Kernel Recipes 2017 edition, up from ~250 patches the year before. About 30% of the total contributions include intentional fall-through annotation of switch cases. He reaffirmed that he really loved Coccinelle, with another 30% of his contributions coming from the tool help.
His work impacted about 939 files, with 1126 email interactions in general. Of those exchanges, he got 3 emails that stood out : “This crap…”, “I hate when…”. He says that’s about 0.27% of the total interaction, so kernel development is 99.73% of pleasure 🙂 ; Gustavo added that he is satisfied with kernel development in general.
Once Gustavo was finished, his talk triggered a discussion on compiler warnings in the room, and on the way they should be enabled or not. Many ideas were proposed, but no conclusion was reached.
That’s it for today ! Continue with the last day morning liveblog.