Welcome to the Kernel Recipes Liveblog !
This is the 7th edition of kernel-recipes, and the first year with an official liveblog.

Kernel Shark 1.0 : what’s new and what’s coming — Steven Rostedt
Steven says that KernelShark, a visual tracing tool, is still progressing and quickly reaching 1.0 release status. They now have a full-time employee working on it at Vmware.

KernelShark is a visual interface to trace-cmd, a frontend for ftrace, a kernel tracing framework. Originally written with GTK+ 2.0, they needed to port it to GTK+ 3.0, but were burned by the porting effort, so they decided to move to Qt.
KernelShark was created to help visualizing text traces, which can be quite hard to understand as they grow.
Steven recounts that time when a customer couldn’t detect a hardware latency, because they had tool to detect them written in Java, with a wrong window of observation. Cyclictest, Steven’s tool could detect them quite easily. But still, it was very hard to understand the text traces for someone not use to ftrace; with KernelShark, everything appears instantly.
KernelShark 1.0 is much faster thanks to Yordan Karadzhov’s rewrite of the core algorithms. It can display the data at a much higher rate. Steven does not claim any authorship, but has been mentoring and reviewing Yordan’s code over the last months, from prototypes to the production phase, which is approaching very quickly, since there’s a conference next month where they want to announce 1.0. Steven calls this “Conference-driven development”.
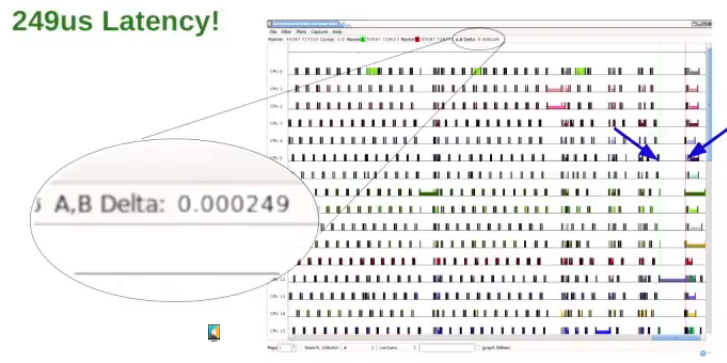
KernelShark’s 1.0 UI has a few different types of “Markers” to locate yourself in the trace : Markers A and B are used to measure differences between points in time in a trace. It’s been simplified since 0.2. You can still zoom-in, but you get more dense information in the zoomed-out views. A lot of efforts has been put in making sure finding what where you’re at in the trace is simpler, and making browsing a trace simpler.
What’s next after 1.0 ? Steven says they want to move all the core algorithms in libkshark.so, a future LGPL library. This will allow you to write your own tracing UIs, without all the efforts of managing ftrace, parsing traces, and understanding the content. Python bindings are also in progress. The goal is to have the core engine in libkshark, that will then be used in many applications.
Future improvements planned include different kind of views (plot views, flame graphs, etc.); as well as showing traces from multiple machines.
To conclude, Steven gave a demo of KernelShark’s new performance, and new UI features.
In answer to a question from the public, Steven clarified that KernelShark’s goal for 1.0 was to be on feature-parity with the previous, GTK version, then add new features, like plugins.
Another question was on the binary trace format, and Steven says that it’s fully documented in the trace-cmd.dat manpage.
XDP: a new programmable network layer — Jesper Dangaard Brouer
XDP stands for eXpress Data Path which arrived recently in Linux. Jesper says the goal of talk is to introduce the rationale and basic building blocks behind this upstream technology, not necessarily dive in too deep in the tech details or learn how to use eBPF.
XDP is designed as a new layer in the Linux network stack, before skb allocation. We can consider this a “competitor” to kernel bypass technologies like DPDK or netmap, but this is not a kernel bypass, Jesper says, since the dataplane is kept in the kernel.
Kernel bypass solutions market themselves as 10x faster than Linux kernel netstacks, which is true, but for their specific usecase. Unfortunately it let some people think that the kernel is inherently too slow to do networking, which pisses off Jesper, and led him to work on XDP.
An XDP goal is to close the performance gap with kernel-bypass solutions, but not necessarily to be faster; another is to provide an in-kernel alternative, that is more flexible, with hooks at the driver level that allow fast eBPF processing, and still keep using the Linux kernel network stack.
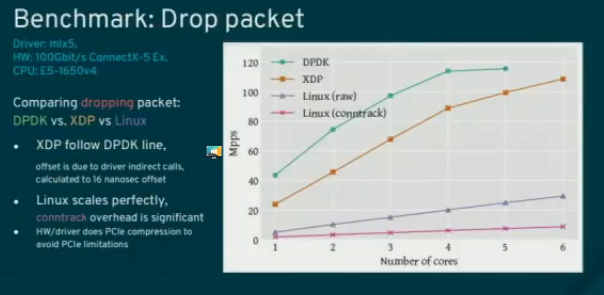
Jesper showed a benchmark, showing how many millions packet per seconds XDP can handle, and how close it has come to DPDK, and even being faster when L2 forwarding packets on the same NIC.
XDP works with BPF programs, which return an XDP action, to decide what to do with a packet: drop it, pass, tx, abort or redirect.
It allows cooperating with the network stack by modifying headers, for example to change the rx-handler in order to handle an unknown protocol by the kernel.
The data plane is still inside the kernel, and the control plane is loaded by userspace through the bpf system call. BPF programs are sandboxed code running inside the kernel. BPF kernel hook provide limited possible actions, while still allowing users to have programmable policies.
XDP_REDIRECT is an XDP action that allows redirecting raw frames to another device. Redirect using BPF maps is a novel feature, because it allows batching through RX bulking from driver code, into a map, delaying expensive flush operations in NIC tailptr/doorbell. Redirecting into a map also allows creating new types of redirect without modifying driver code, so Jesper is hopeful that this will be the last XDP action, which need driver support.

There a few BPF-level redirect map types: the devmap type allows redirecting te a given network device; the cpumap type allows redirecting a raw XDP frame to another CPU thread where the kernel will do skb allocation and traditional netstack handling. The xskmap, allows redirecting raw XDP frames into userspace through the AF_XDP socket type.
Spectre V2 countermeasures killed XDP performance with the retpoline indirect call tricks. It’s still processing aobut 6M packets per second per CPU core, but it used to be about 13M before. Jesper can’t just disable retpoline entirely, but there are solutions in the pipeline, which will require improving the DMA use, as shown by Christoph Hellwig in a proof of concept.
Jesper then showed how to move from NDIV to XDP. NDIV is a custom kernel solution by Willy Tarreau (presented a few years ago at Kernel Recipes), which never went upstream, but is in use in HAProxy. Jesper showed an architecture to offer all the features needed by HAProxy with XDP. Whether this would then be upstreamable or not is still to be determined though.
Jesper finished by insisting that XDP is a combined effort of many people, and thanking them.
A remark from the audience was that XDP’s integration with the kernel, allowing to inject packet in the netstack very easily is a huge advantage over other kernel bypass technologies. In response to a question, Jesper than shared an optimization trick, where reducing the size of an internal ring buffer allowed reducing the number of cache misses (as measured with perf), and then greatly improving the results.
Since time permitted, Jesper continued on to explaining in more details how the cpumap redirect work. The main goal is to send a raw XDP frame to the network stack, without the impact of a deep call into the netstack, since the call happens on a different CPU, allowing it to be processed concurrently, and the small eBPF program continues working without moving out of the CPU cache. cpumap uses a few in-kernel tricks and integration with the scheduler, using kthread enqueuing, to make sure the multiple-producers single-consumer model works well.
CPU Idle loop rework — Rafael J. Wysocki
Rafael has been maintaining multiple subsystems from cpuidle to cpufreq and power management.
He started by introducing the terminology: how to differentiate a CPU core, or a Logical CPU when SMT is taken into account (HyperThreading), in this case the scheduler see them as independent core.
As defined in Linux, a CPU is idle when it has not given task to execute. It does not necessarily mean that no code is running on it. But Linux also uses this idle state to reduce the power consumption of the CPU.
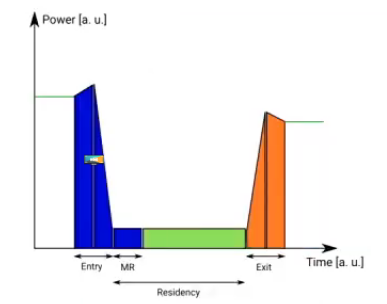

There’s a fist step to prepare for lower level of power consumption: first phase (Entry), where power consumption will slightly increase. Then a similar phase when going out of lower levels (Exit). Both of these add incompressible latency, which needs to be taken into account before deciding to reduce the power level.
On Intel hardware, the idle states translate to C-states. But the C-states concern CPU cores, not necessarily Logical CPUs, so there needs to be coordination, and understanding at kernel-level of the package layout and relation between logical CPUs, and what forms a CPU core.
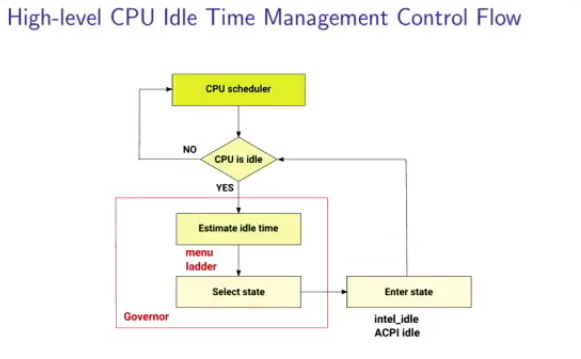
The high-level CPU idle time decision algorithm requires interaction between a few components: the CPU scheduler, which decides when a CPU should be idle. Then there are idle governors, two at the moment: menu and ladder, which estimate the idle time, and then select a state.
When entering the state, this is handled by the drivers, for example intel_idle or ACPI idle.
This high-level view looks simple enough:
But there are complications. The CPU Schedule Tick timer still needs to run regularly, but it can be stopped when there are no tasks to run, since it’s going to be idle anyway. So the original design implemented is a follows, stopping the tick upfront, before deciding whether or not the idle time would short or long:
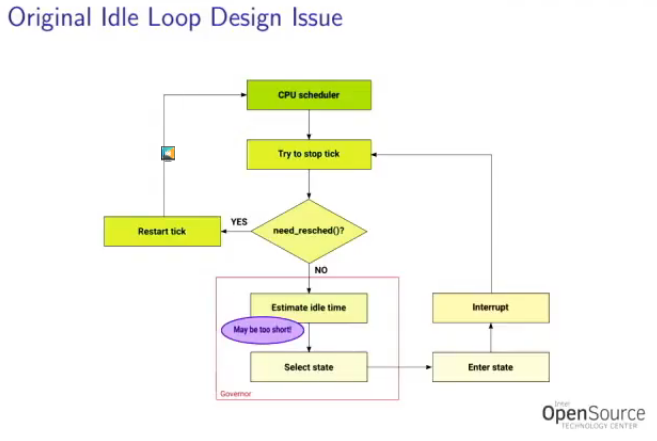
This unfortunately was not good for short idle times, since it did not necessarily need to stop the tick, and would then lead to longer-than needed idle times, and more latency. It also caused an issue with the idle governor, which handled two source of information, one of which was non-deterministic.
The “menu” Idle Governor takes information from the NOHZ infrastructure to determine the next timer event, and from the CPU scheduler utilization information, and then computes an Idle time range, which is used in conjunction with last wakeup statistics to predict an idle duration. But the wakeup statistics might be influenced by repetitive timers, which doesn’t make sense.
So this was rewritten in 4.17, where the Idle governor decides whether or not stop the scheduler tick. But the governor also needs to be changed to take into account the next timer event. So it was integrated with the NOHZ infrastructure as well.
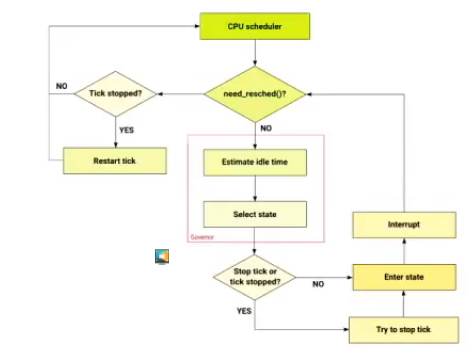
Rafael showed results where the power consumption of Intel servers was reduced after the Idle loop redesign. But these improvements, Rafael says, were a side-effect of the idle-time improvements. These power improvements also didn’t directly affect laptops, since they don’t have the same type of instrumented workloads.
That’s it for this morning ! Continue with the afternoon updates !