
Welcome back to the live-blog, this continues from this morning’s liveblog!
Where does my memory come from? — Lorenzo Stokes
When allocating memory with malloc (which uses mmap or brk), the kernel does not necessarily reserve memory, it does that lazily, via VMAs.
“If you have sane hardware, the memory is virtual”, so Lorenzo introduces the way virtual addresses and its mapping via the page tables, via multiple levels of PGD, (P4D), PUD, PMD and PTE to map from 128TiB to 64PiB of user memory.
When userland tries to access memory that doesn’t have corresponding page tables, it trigger a pagefault, which the kernel handles: it will either allocate page tables if it’s valid, or send a SEGFAULT to the user process.

For Physical Allocations, the kernel uses a buddy allocator, which will divide blocks in power of twos, and then coalescing them on free. Metadata to describe virtual mappings is stored in Folios.
Then there is the notion of Anonymous vs File-backed. But what it means in the kernel to be “anonymous” varies between folios and VMAs. Lorenzo says it’s better to think in term of swap-backed vs file-backed (even then, there are edge-cases like shmem).
Under memory pressure, the kernel might use Reclaim as a mean to free memory (broadly it’s an LRU cache). Lorenzo showed how the active and inactive LRUs are used for file-backed and swap-backed memory.
For Swap, a page that is swapped-in will then fault; for swapped-out it’s the reverse. During compaction and migration, memory might even be moved physically.
To summarize, this is how an allocation might look like: 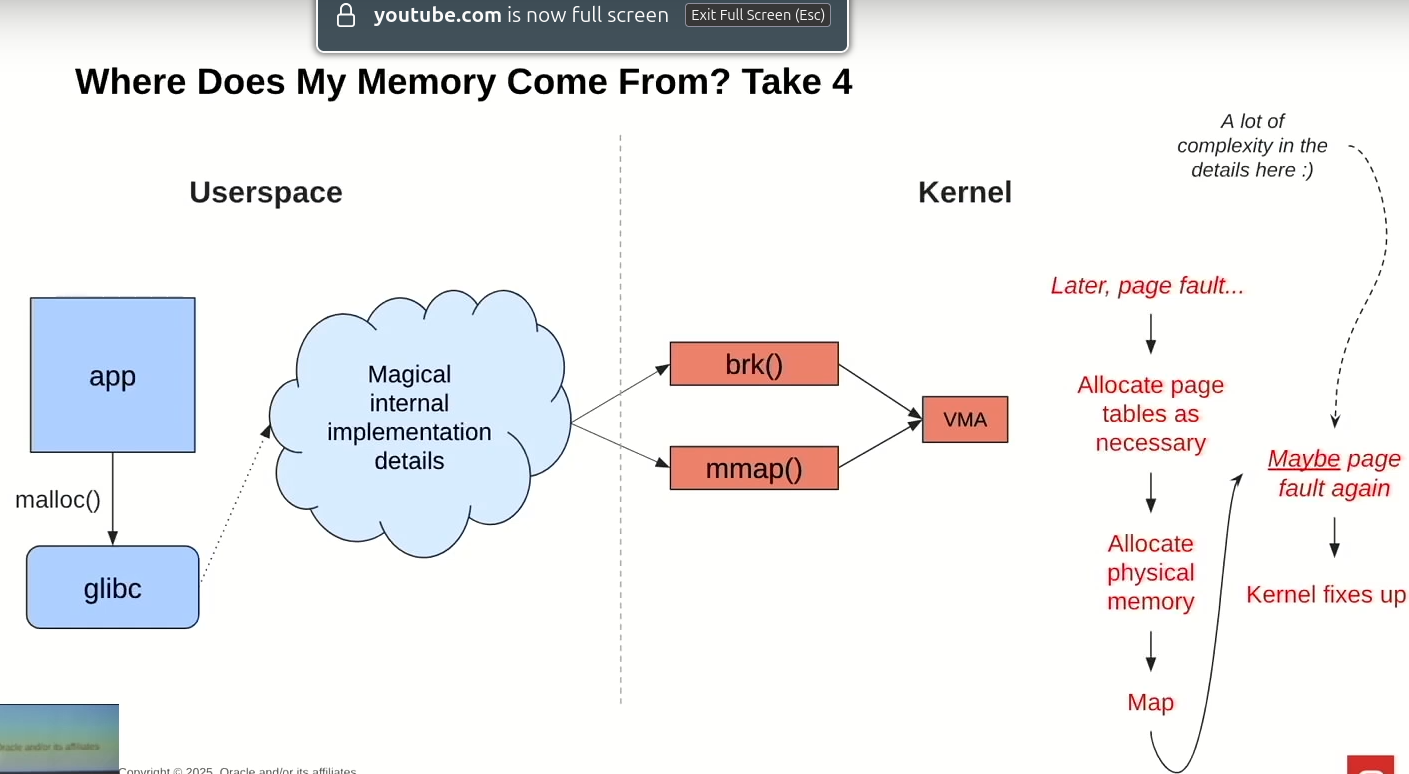
We had questions from the audience regarding details on RSS or crgroup accounting: both Lorenzo and other mm maintainers from the audience went into the details. Matthew Willcox also answered a question about the difference between struct page and struct folio, sharing his plan to reduce struct page size in the future (down to 32 bytes in 2025, 8 bytes later). Someone asked which part was hardware-assisted; the way page table levels are managed is entirely hardware.
Linux Virtualization Based Security (LVBS): What, Why and How — Thara Gopinath
LVBS’s goal is to improve the security posture of Linux by using the hypervisor/kernel security boundary. It’s motivated by a rising number of attacks to the kernel; Thara cited SLUBStick as an example.
 Kernel Hardening is done by adding hypervisor verification when loading modules for example (HEKI); the goal is also to support a TEE-like environment for trusted applications (Secure Enclaves).
Kernel Hardening is done by adding hypervisor verification when loading modules for example (HEKI); the goal is also to support a TEE-like environment for trusted applications (Secure Enclaves).
The threat model in which LVBS functions is the following: the kernel is benign, but vulnerable. The guest kernel can be trusted until the first user space process starts running.
LVBS’ goal is to have a fully-open hypervisor-agnostic solution, that can work regardless of the CPU architecture TEE environment.
Hypervison Enforced Kernel Integrity (HEKI) is a pass-through layer to call into the hypervisor. The API of HEKI can be used to validate module loading, unloading, text section patching or key management. The goal of heki_text_poke is to support static calls, ftrace or jump labels, but it’s still controversial.
LVBS supports Optee, and it was chosen because it’s an active project, and will be used for Secure Enclaves.
Hyper-V is Microsoft’s hypervisor, and LVBS integrates with it.
For the Secure Kernel, LVBS evaluated multiple solutions for its “Secure Kernel”; it converged on Rust Based minimal firmware, that is still internal to Microsoft at the moment, but will be open-sourced in the future.
KVM integration is in progress, with initial patches posted to implement MBEC and register pinning in host KVM. Another approach is adding VM Planes, proposed by Paolo Bonzini.
The project is open to collaboration for reviewing Heki code, VMplanes, implementing VTLs, or adding x86_64 support to Optee.
Here is how LVBS compares to Confidential VMs: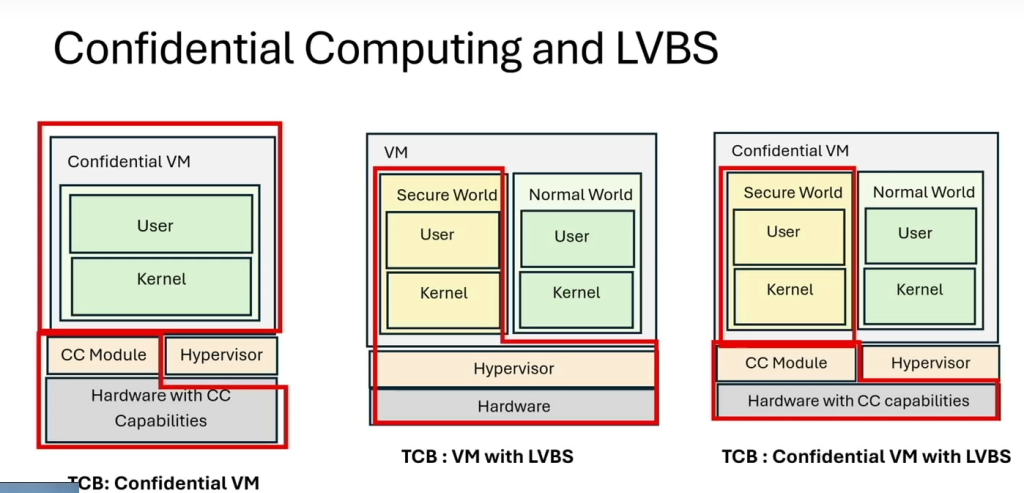 LVBS can work with both a classic hypervisor or a confidential VM.
LVBS can work with both a classic hypervisor or a confidential VM.
Schedule recipes — Andrea Righi
A scheduler is kernel component that determines when, where and for how long a task needs to run. It allocates across space (CPU) and time (task). sched_ext is the extensible scheduler class, a technology in the kernel that allows writing safe schedulers, verified by eBPF, and it cannot crash the machine. A userspace program loads the BPF program into the kernel, and it can also communicate with it in an efficient way.
 In userspace, libbpf helps writing those programs; it has Rust bindings in libbpf-rs. sched_ext has had a lot of success in gaming; in particular, in competitive gaming, people care about consistency (lack of jitter). Another example is the Llama benchmark, where Nvidia has been able to get ~2.6x more throughput (tokens/s) on CPU inference.
In userspace, libbpf helps writing those programs; it has Rust bindings in libbpf-rs. sched_ext has had a lot of success in gaming; in particular, in competitive gaming, people care about consistency (lack of jitter). Another example is the Llama benchmark, where Nvidia has been able to get ~2.6x more throughput (tokens/s) on CPU inference.
While Andrea does not have time to go into details, he can share ingredients that are used. The first one is the shared runqueue. It’s theoretically the most efficient for throughput and average wait time. But it has issue in real-life: there are more migration than needed; and handling the concurrency of a single queue is a challenge. Locality can be improved with Per-CPU runqueues, but it has issues with work conservation. It all depends on the context. For example, in gaming the shared runqueue often works better.
Runtime allocation (fairness) is another challenge. And modern CPU systems have complex topologies, with shared caches, numa nodes, big/LITTLE, etc. It is “non trivial” to pick the best general solution, Andrea says.
Another complex problem is Task wake-up: should the wakee run on its previous CPU, or on the waker CPU? It depends on which data the wakee will use.
Recipe #1: the empty scheduler
This one implements no callback at all (except exit for cleaning), and will use sched_ext’s default implementation. It’s running pretty well if you don’t have too many CPUs. In some cases, it will perform better than the default scheduler.
Recipe #2: the global vs shared runqueue scheduler
This is the small scx_rrsample; using the a runqueue per CPU, Andrea showed an example using the WebGL Aquarium, and running stress-ng in parallel: the FPS drop a lot when stress-ng is started; Andrea showed the difference between global and per-cpu runqueue: without load balacing, the per-cpu runqueue exhibits issue in distributing work.
Recipe #3: The “yell at your PC” scheduler
This one assigns more CPUs based on the noise level around your PC. Andrea had the audience clapping to improve CPU performance and doubling the Aquarium FPS. A nice side effect, is that it saves power when the environment is quiet.
To conclude, Andrea says that the one-size-fits-all is no longer enough. It’s possible to build hybrid schedulers, and there is a great potential in being able to offload decisions to user space.
In the audience, Aurélien Rougemont recommended to use Perfetto when experimenting with sched_ext, to be able to view what is going on with the scheduler. A long discussion ensued on the pros and cons of waker vs wakee CPU task allocation.
BPF OOM: using eBPF to customize the OOM handling — Roman Gushchin
As warning to junior kernel engineers, Roman showed a comment in the OOM source code saying that it’s “simple” and a good example to start coding. It was not, Roman says.
 In 2017, Roman started by making the Out Of Memory (OOM) killer cgroup aware, which posed a few interesting challenges regarding decision making across cgroup trees, processes, etc. It did not make it upstream.
In 2017, Roman started by making the Out Of Memory (OOM) killer cgroup aware, which posed a few interesting challenges regarding decision making across cgroup trees, processes, etc. It did not make it upstream.
Then in 2018, someone else worked on PSI, a new metric to detect thrashing, on top of which oomd was implemented, and later systemd-oomd. It was not meant to fully-replace the in-kernel oom killer, but work in conjunction with it.
Later this year, Roman worked on memory.oom.group, so that a full cgroup can be killed when a single process of the cgroup is killed: this helps some workloads that are co-dependent in a cgroup, and made it upstream because it was not controversial, and the algorithm stayed cgroup-independent.
In 2023, Chuyi Zhou suggested using bpf for picking the OOM victim, using a hook called for every task; it wasn’t integrated, but it laid the foundation for the next iteration integrating open cgroup and task iterators.
In 2025, Roman started working on this again with bpf psi and bpf oom. In bpf psi, there are three callbacks: init, handle_psi_event, and handle_cgroup_free. They allow writing a bpf program to handle psi triggers. There is the bpf_out_of_memory kfunc, to be able to trigger an OOM from bpf. Roman showed an example of test program killed with bpf ps: the oom constraint is properly set in the dmesg so one can understand where the OOM comes from.
With bpf oom, there is only a single callback handle_out_of_memory, and Roman showed how to implement it in bpf. Roman says it should be more reliable than the userspace oom killer, because it should behave like the kernel oom killer. It uses the bpf_oom_kill_process kfunc to kill the target process. The oom policy and constraints are also shown in this case.
This functionality is currently at v1, and v2 will be sent for review soon. In the future, Roman want to explore having multiple oom policies in the system. With bpf psi it already works, because each attached bpf program can work independently. It’s a bit harder for bpf oom. Another challenge would be to attach the bpf programs at the container level instead of system level.
That’s it for today! Continue reading the next episode!
0 Comments