
You can read the morning talks report here.
Kernel hacking behind closed doors — Thomas Gleixner
In the kernel, the security bugs are handled by the security team, which decides whom to bring to address specific issues, which would then be fixed and shipped within seven days. For a long time it worked relatively well, bugs were being fixed, and it was routine.
But two years ago, hardware security bugs appeared that had to be fixed in the kernel: it was the speculation attacks. Suddenly, the old way of doing didn’t work: fixes had to be coordinated with other (OS) vendors. The playbook just didn’t work anymore.
For Spectre and Meltdown, Intel took charge of the coordination between vendors; but multiple Incident Response teams inside Intel were handling different vendors, and they just could not communicate with each other. When public disclosure happened, all vendors had different patches in their trees with different type of brokenness.
When the Kaiser patches were posted, Thomas was tipped on the context of the speculation attacks, and forced to look at the patch series. After lots of cleaning, this turned into KPTI, which was merged partially very quickly, which felt to many as something very weird. And that was just for Meltdown, and Spectre was still around the corner.
When Spectre was disclosed, a few day before the deadline, three patches addressing it were posted. But they were all broken, Thomas says. Discussion was very confused on the mailing lists because of the lack of documentation. It was “panic engineering” as Thomas calls it.
That led him to send an email that to ask a few yes/no questions to understand all the implications, and then to reset all the panic by taking some time to go back into “normal mode”.

Later, an agreement was reached between community of vendors for industry-wide collaboration, to have an upstream-first policy and no compartmentalization.
Unfortunately, LKML couldn’t be a good forum for this type of discussion; after a small test of Keybase IO (an encrypted slack-like chat), the decision was taken to use encrypted mailing lists. After trying an existing project, he decided it was too buggy and un-patchable.
That’s why Thomas started hacking on a small python project to handle encrypted emails — he had it up and running three days later handling S/MIME and PGP. It broke a few corporate mail servers by having the spam checker running out of memory. The mail servers would just crash, and the backlog would grow. After a few denial of services, the server was whitelisted.
His code evolved and was later published.
Unfortunately, the disclosure and handling was still controlled by Intel, and its lawyers only understood NDAs, which weren’t workable in the kernel community. That’s why a new formal process was created, with a few public Security officers (Thomas, Greg and Linus) that are Linux Foundation fellows. It was designed exclusively for hardware security issues, with strict disclosure rules for kernel developers to avoid any potential conflict of interests across vendors; those rules were formalized in a Memorandum Of Understanding, that relied on trust.
This process brought wide Industry acceptance, with all the major players agreeing. Thomas only hopes that it won’t be necessary before he retires, but he knows that it’s only wishful thinking.
What to do when your device depends on another one — Rafael Wysocki
In a modern computer, or mobile phone, devices depend on one another.
The simple case is the Tree topology. In that case there’s nothing to do, and the driver core will handle this automatically. Rafael showed a power management example: during suspend, all childen are suspended first, and during wakeup, it’s the opposite.
But if there is a dependency that does not match the tree topology, it more complicated.
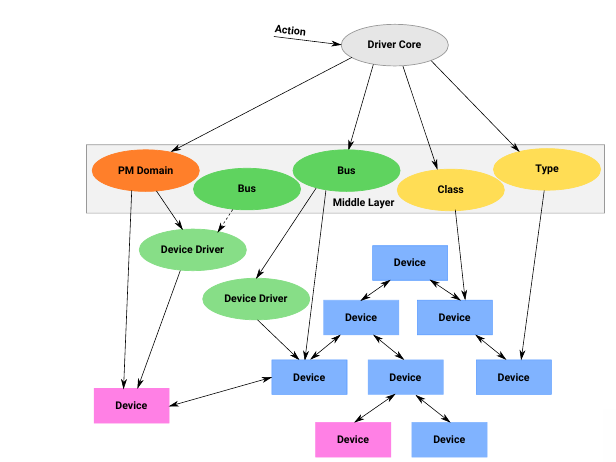
An example of a lightweight solution to this dependency problem is a device links data structure. This helps encode dependencies that aren’t part of the tree:
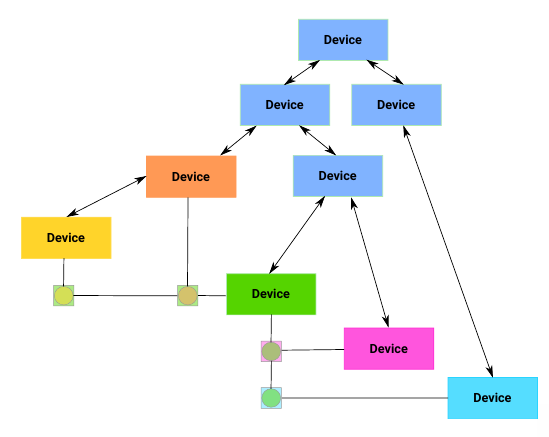

This list should be in the proper order for shutdown ordering. This order should be separated from the driver probe order.
Another usecase for this is PM-runtime ordering. This is used at runtime to suspend unused devices in order to save power.
The third version of device links was merged recently in 4.10. But it still needed rework, and the latest updates should be in Linux 5.4.
There are different types of device links; the managed device links allow the driver core to make decision on the probing and, removal or suspend of a given device, depending on the provided flags, and if a device is a consumer or supplier.
The stateless device links encode a type of dependency that doesn’t cause the driver core to impact probing or suspend. It’s a kind of soft dependency.
When adding a device link, only the supplier device needs to be registered. Circular dependencies are detected when adding a link (returns an error). Stateless device links require cleanup, while managed device links do not.
In order to add a dependency, one device driver can get a pointer to the supplier or consumer on the other side by using the Device Tree phandles, ACPI companion, or some other layer.
There is an internal state machine for the managed device links:
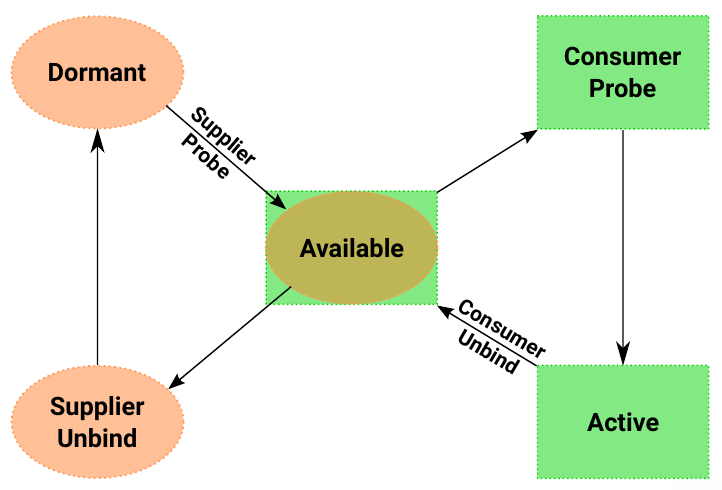
There are a few rules regarding device links flags that are documented. and should be followed depending on the type of device links. There are already users in-tree, and patchsets posted to build more features on top of device links, like complex driver dependencies.
Metrics are money — Aurélien Rougemont
Aurelien has been working in IT operations for 19 years, and has seen many bugs waking him during on-call. He wants to relate some of those.

The first one, starts with load average. It’s a very complex thing to understand, especially since Linux has a very specific way of computing it.
A colleague of Aurélien added a new very common switch to the infrastructure, replacing an old home-made one. After adding monitoring to it, he noticed something very weird: more than 50% of packet loss. That’s when Aurélien was called in for investigation. He found that it might be related to an old kernel bug that had been fixed, but they could not upgrade due to a binary driver. He dug into the documentation and finally found what was needed to do in order to fix the metrics collection. Unfortunately, based on wrong metrics, the network capacity had been upgraded in advance and cost the company 2.8M euros.
Another issue was a new SFP+ adapters which did not have proper ethtool metric. Aurélien wret a kernel patch to add those metrics, which helped find 480 faulty SFP+ in a new batch of hardware. They were sent back, saving the company 200k+ euros.
In a product Aurélien worked on, it used various disks with a ZFS raid array. But when receiving a new disk batch, Aurélien noticed a performance discrepancy between the disks: there were good ones, and bad ones. The bad ones were reported to the manufacturer, which after lots of fighting and sharing proofs of bad performance, the manufacturer agreed to change, saving the company 150k+ euros.
Aurélien’s point is that metrics should be always used, but being careful of taking automated decisions based on those metrics: always look carefully if you’re measuring what you want to be measuring.
In conclusion, Aurélien says that one shouldn’t think that kernel code is sacred. Go read the code, the git history per subsystem, and don’t be afraid to contribute, even if your first few tries will be bad. Even bad patches can help kernel developers understand what’s missing from the documentation.
No NMI? No Problem! – Implementing Arm64 Pseudo-NMI — Julien Thierry
An IRQ is a manifestation of an event in the system: from a device or program. It interrupts the normal flow of execution.

A Non-Maskable Interrupt (NMI) is an interrupt that can still happens when interrupts are disabled. In x86, there’s a dedicated exception entry for NMIs. In Linux, there’s a specific context for NMIs with nmi_enter() and nmi_exit(); it informs system-wide features like printk, ftrace, rcu, etc. It puts a few restrictions in place: no NMI nesting, no preemption which help keep the NMI handlers simple.
In an NMI handler, it’s not possible to use a spinlock, because they can’t protect against interrupt: one should just use a mutex instead.
NMIs can be useful for perf. Julien showed an example on arm64, where during a long perf record, perf would use the performance record unit, and the IRQ restore code would be at the top of CPU usage. That’s because, when restoring IRQs, all pending interrupts need to be processed, thus their impact being recorded at IRQ restore time.
In arm64, interrupts are being handled by the Generic Interrupt Controller (GIC), which wakes up the CPU through the GIC PMR interface, which then sets the PSTATE.I bit. In order to implement NMIs in Linux, the goal is to stop touching PSTATE.I bit, and mask IRQs using PMR instead. The high priority NMIs would then be configured directly in the GIC.
Julien finally submitted an implementation of NMI interrupts upstream, which really helped perf profiling to be accurate of when events happened, during masked-interrupts contexts. The patches were merged in Linux 5.1, with important fixes in 5.3. It needs an aarch64 platform with GICv3 to work.
This liveblog is done for this first day. Read the second day posts here.
Trackbacks/Pingbacks